Context Augmented Dynamic Bayesian Networks for Event Recognition
Xiaoyang Wang and Qiang Ji
Intelligent Systems Lab, Rensselaer Polytechnic Institute, Troy, NY
Introduction
We propose a new Probabilistic Graphical Model (PGM) to incorporate the scene, event object
interaction, and the event temporal contexts into Dynamic Bayesian Networks (DBNs) for event
recognition in surveillance videos. We first construct the baseline event DBNs for modeling
the events from their own appearance and kinematic observations, and then augment the DBN
with contexts to improve its event recognition performance. Unlike the existing context
methods, our model incorporates various contexts simultaneously into one unified model.
Experiments on real scene surveillance datasets with complex backgrounds show that the contexts
can effectively improve the event recognition performance even under great challenges like large
intra-class variations and low image resolution.
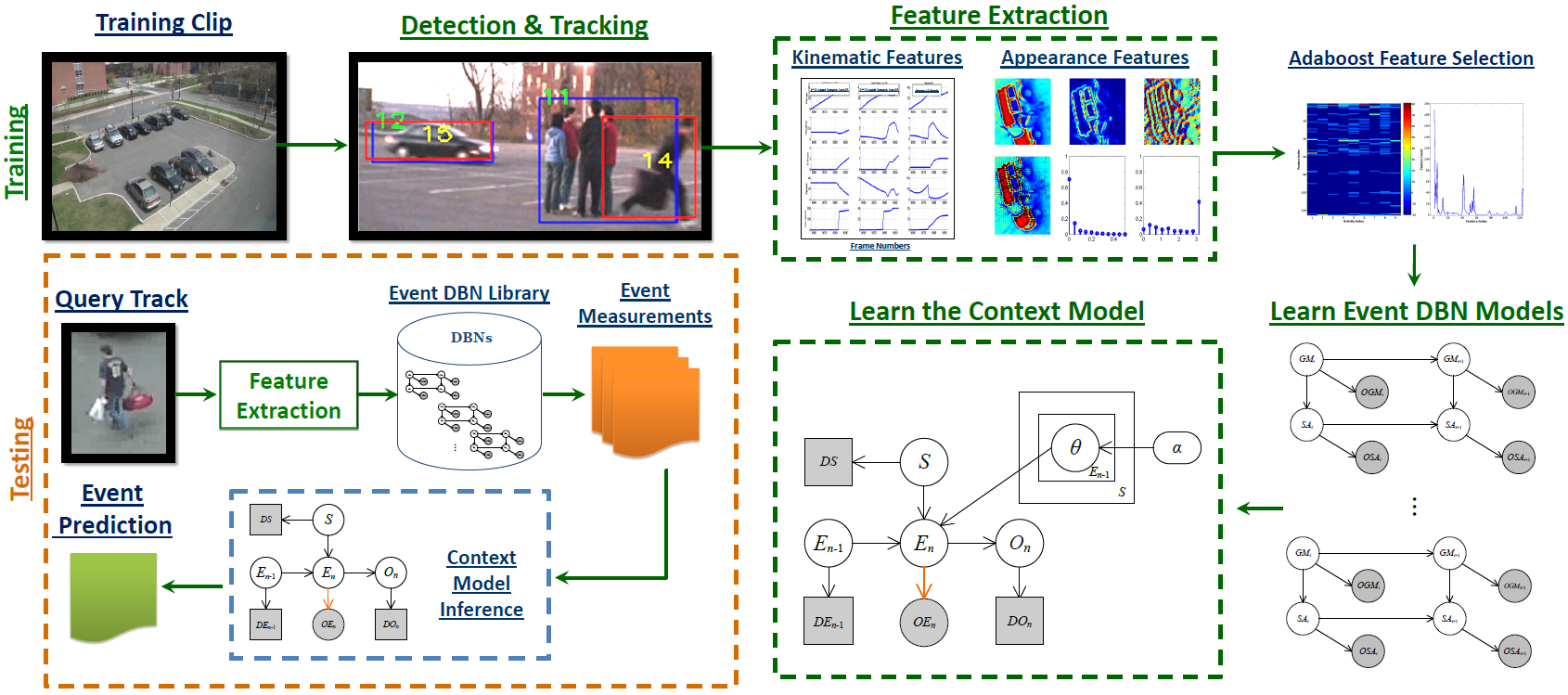
Overall Approach
We propose to use a probabilistic graphical model that incorporates various contexts into the
dynamic DBN model for event recognition. The following figure gives the overall framework of
our event recognition system. During training, given multiple training clips, target detection
and tracking is performed first, and then the system extracts features from the tracks of the
training clips. After the AdaBoost based feature selection, the baseline event DBN models are
learned based on the selected features. Also, we utilize the static object, scene and event
temporal relation information in the training data as contextual information to train the
context model. During testing, given a query track, we extract the features, and then use the
baseline DBNs in the event DBN library to obtain the event measurements. These event measurements
are combined with the scene measurement, object measurement and the previous event prediction to
jointly infer the current event type using the proposed context model.
Baseline DBN Model
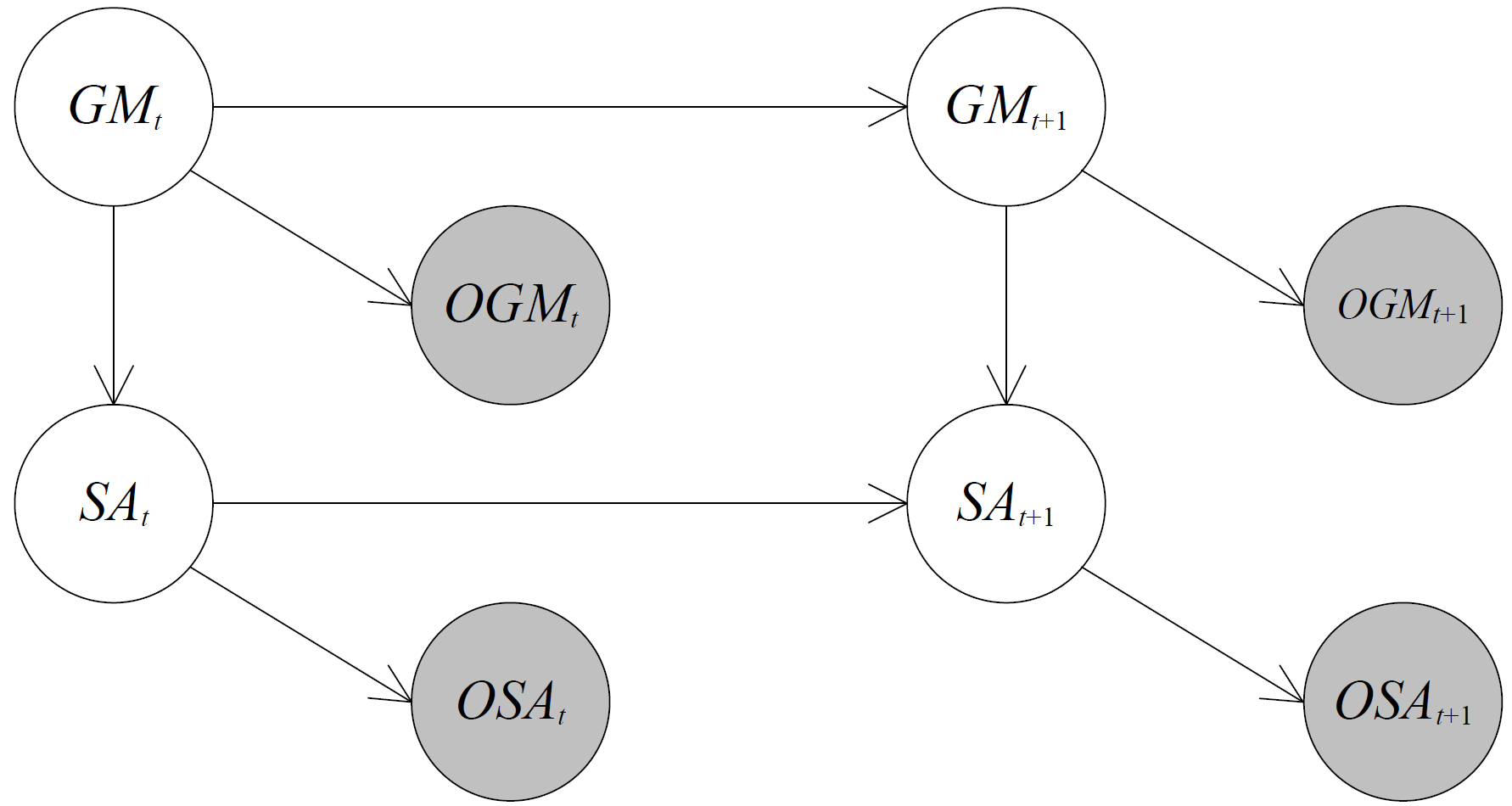 |
As shown in the left figure, our baseline DBN model for event recognition consists two layers.
The top layer includes two hidden nodes GM and SA respectively. The GM node represents the global motion state,
and the SA node represents the shape and appearance state. The bottom layer consists of two measurement nodes
OGM and OSA. The OGM node denotes the kinematic features extracted from the global motion measurements. The
OSA node denotes the HoG and HoF image features extracted from the appearance measurements.
Besides the nodes, there are two types of links in the model: intra-slice links and inter-slice links. The
intra-slice links couple different states to encode their dependencies. And, the inter-slice links represent
the temporal evolution and capture the dynamic relationships between states at different times. The proposed
DBN model is essentially a coupled HMM, that captures dynamic interaction between target motion and its
appearance over time.
To model K types of events, we build in total K such DBN models, each corresponding to one type of event.
|
Contexts for Event Recognition
We use three types of contexts for event recognition in surveillance videos: scene context, event-object interaction
context, and the event temporal context.

-
Scene Context
Events in surveillance videos are frequently constrained by properties of scenes and demonstrate high correlation
with scene categories. E.g. events in parking lot (would include events like "loading a vehicle", "getting out
of a vehicle" etc.) are different from events in playground (would include events like "jogging", "running"
etc.). Knowledge of the scene categories can hence provide a prior probability of the events when utilized as scene
context.
-
Event-object Interaction Context
Static objects that interact with the events would provide valuable clues for recognizing the events. E.g. person
"walking" on sidewalk, and person "getting out of vehicle" aside vehicle, as shown in the Figure (a) above.
The interacting objects sidewalk and vehicle would provide valuable information to judge whether the
event is "walking" or "getting out of vehicle", even if the kinematic and appearance properties of the target persons
are similar. We can utilize these interacting objects as event-object interaction context to help infer the event type.
-
Event Temporal Context
Event occurrence is also constrained by the natural temporal causalities of executing events. E.g. event
"closing a trunk" typically follows event "loading/unloading a vehicle", while event "walking" often
precedes event "getting into vehicle", as shown in Figure (b) above. We utilize the previous
event as event temporal context to provide a clue for the current event prediction.
Context Model
We systematically incorporated the three contexts (i.e. the scene context, the event-object interaction context, and the
event temporal context) into one context model, and use this model to infer the posterior probability of events given event
observation and different context measurements. The model graph is shown below.

As shown in Figure (a) above, event nodes E (both En-1 and En) have K discrete values where K stands for the K different
categories of events. The subscripts n-1 and n on E nodes stands for the events at two different times, where En-1 stands
for the previous event, and En stands for the current event. The link between En-1 and En captures the temporal dependency,
i.e. the event temporal context. The S node stands for the scene. The link between S and En captures the causal influence
of the scene context on event. The On node stands for the contextual object for current event clip. The link between En
and On captures the event-object interaction context. During testing, all these four nodes En, En-1, S and On are unobserved,
with their corresponding measurement nodes OEn, DEn-1, DS and DOn as estimates of their states.
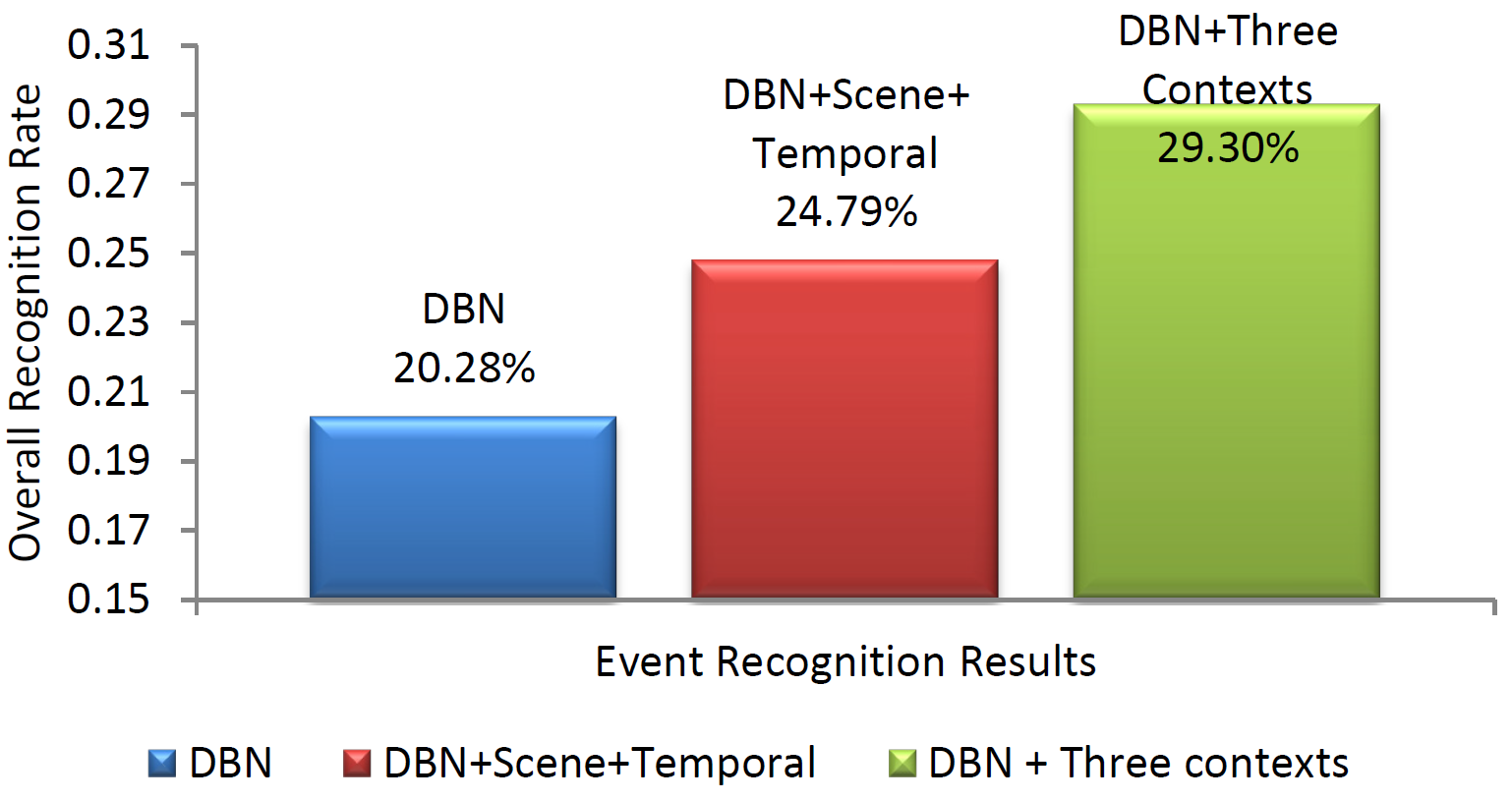
Experimental Results
Here, we present the overall result for event recognition on the mixed dataset of VIRAT public 1.0 and VIRAT aerial datasets.
Compared to other common activity datasets like KTH, Weizmann, and HOHA, these two datasets are very challenging.
They are collected in real scenes with low resolution. Also, they focus on complex events which include the interactions
between persons and vehicles. These complex events are more difficult to recognize than the simple events like walking or running.
For recognizing eight events including Loading a Vehicle, Unloading a Vehicle, Opening a Trunk, Closing a Trunk,
Getting into a Vehicle, Getting out of a Vehicle, Entering a Facility, and Exiting a Facility, our context
model can improve the baseline DBN model for over 9%.
Publications
[1] Xiaoyang Wang, Qiang Ji, "Video Event Recognition with Deep Hierarchical Context Model", in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4418-4427, 2015. [PDF]
[2] Xiaoyang Wang, Qiang Ji, "A Hierarchical Context Model for Event Recognition in Surveillance Video", in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2561-2568, 2014. [PDF]
[3] Xiaoyang Wang, Qiang Ji, "Incorporating Contextual Knowledge to Dynamic Bayesian Networks for Event Recognition", in Proceedings of the 21st International Conference on Pattern Recognition (ICPR), pp. 3378-3381, 2012, (Oral Presentation). [Piero Zamperoni Best Student Paper Award] [PDF]
[4] Xiaoyang Wang, Qiang Ji, "Context Augmented Dynamic Bayesian Networks for Event Recognition", in Pattern Recognition Letters, 2013. [PDF]
© Copyright 2014. All rights reserved.