
The Intelligent Systems Laboratory at RPI has long performed research related to human gesture, action, and activity recognition. Specifically, we have performed research in human body detection and tracking, 2D/3D body pose estimation, body landmark/part detection and tracking, body gesture recognition, human event and complex activity recognition. These efforts have been supported by different governmental agencies including DARPA, ARO, ONR, AFOSR, DOT, and NSF.
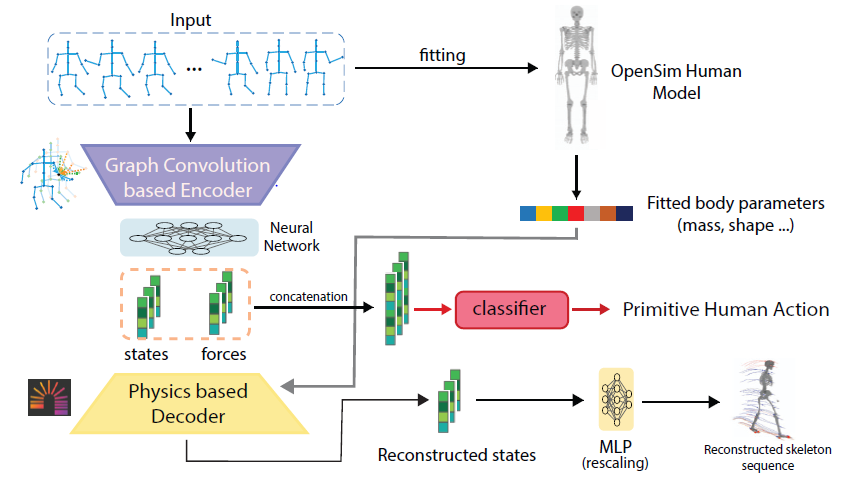 |
Hongji Guo, Alexander Aved, Coller Roller, Erika Ardiles-Cruz, Qiang Ji SPIE DCS 2023 In this work, we propose a physics-augmented encoder and decoder model that produces physically plausible geometric features for human action recognition. Specifically, given the input skeleton sequence, the encoder performs a spatiotemporal graph convolution to produce spatiotemporal features for both predicting human actions and estimating the generalized positions and forces of body joints. The decoder, implemented as an ODE solver, takes the joint forces and solves the Euler-Lagrangian equation to reconstruct the skeletons in the next frame. By training the model to simultaneously minimize the action classification and the 3D skeleton reconstruction errors, the encoder is ensured to produce features that are consistent with both body skeletons and the underlying body dynamics as well as being discriminative. The physics-augmented spatiotemporal features are used for human action classification. |
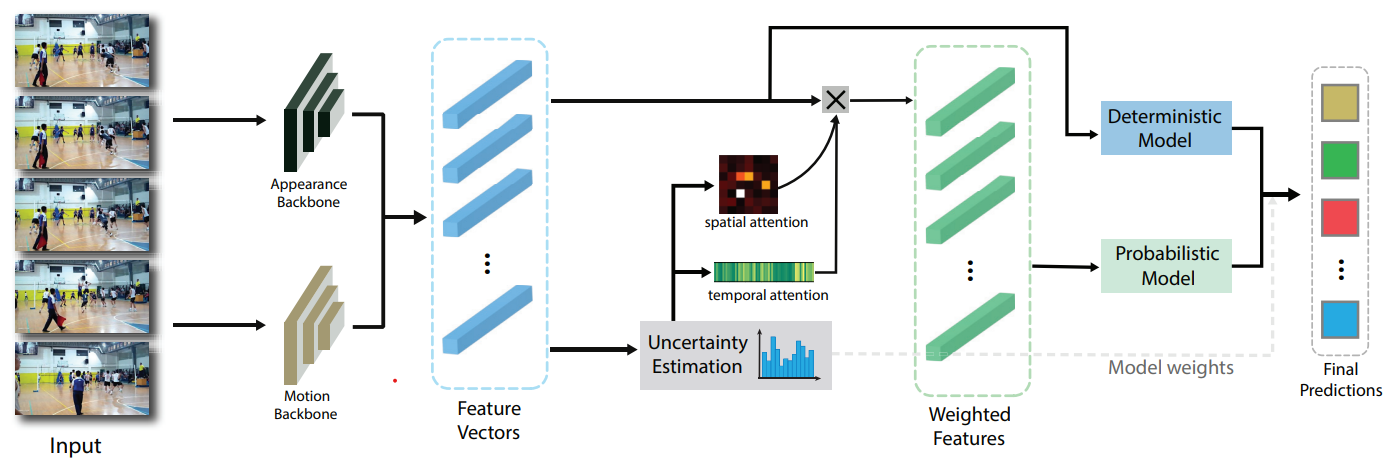 |
Hongji Guo, Zhou Ren, Yi Wu, Gang Hua, and Qiang Ji ECCV 2022 [Project Page] Online action detection aims at detecting the ongoing action in a streaming video. In this paper, we proposed an uncertainty-based spatial-temporal attention for online action detection. By explicitly modeling the distribution of model parameters, we extend the baseline models in a probabilistic manner. Then we quantify the predictive uncertainty and use it to generate spatial-temporal attention that focus on large mutual information regions and frames. For inference, we introduce a twostream framework that combines the baseline model and the probabilistic model based on the input uncertainty |
 |
Rui Zhao, Hui Su, and Qiang Ji CVPR 2020 We proposed a generative probabilistic model for human motion synthesis. It has a hierarchy of three layers. At the bottom layer, we utilize Hidden semi-Markov Model(HSMM), which explicitly models the spatial pose, temporal transition and speed variations in motion sequences. At the middle layer, HSMM parameters are treated as random variables which are allowed to vary across data instances in order to capture large intra- and inter-class variations. At the top layer, hyperparameters define the prior distributions of parameters, preventing the model from overfitting. |
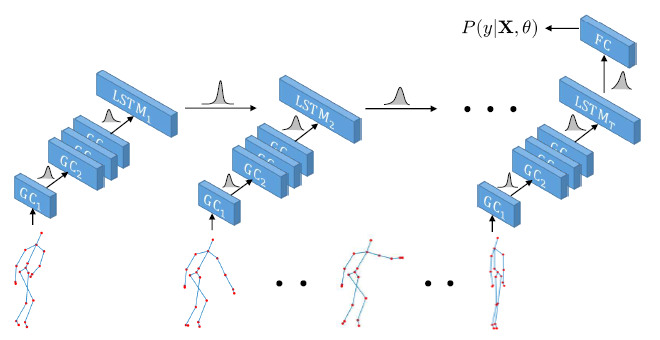 |
Rui Zhao, Kang Wang, Hui Su, Qiang Ji ICCV 2019 We utilize graph convolution to extract structure-aware feature representation from pose data by exploiting the skeleton anatomy. Long short-term memory (LSTM) network is then used to capture the temporal dynamics of the data. Finally, the whole model is extended under the Bayesian framework to a probabilistic model in order to better capture the stochasticity and variation in the data. |
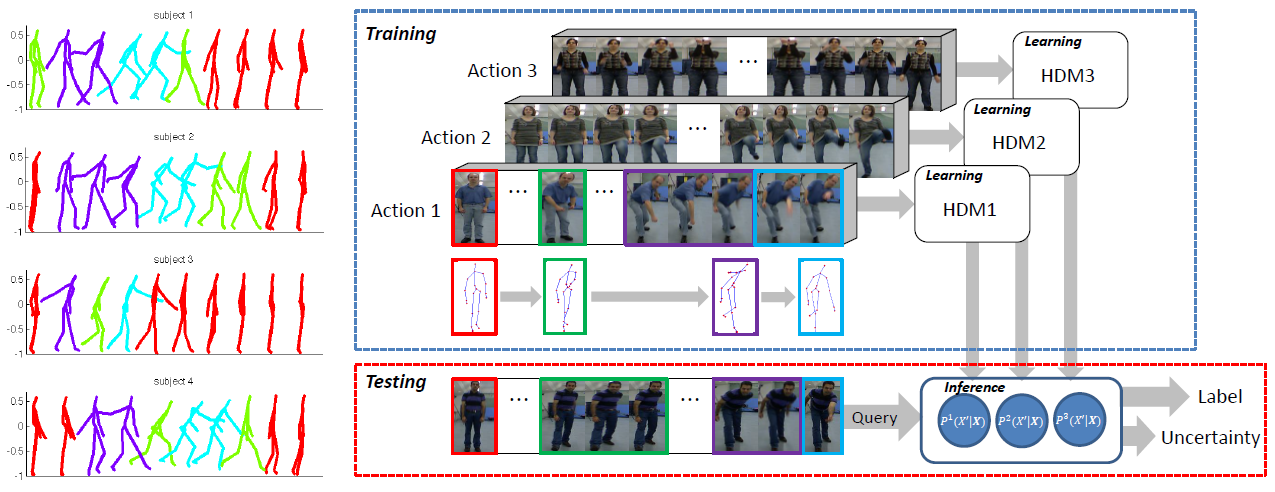 |
Rui Zhao, Hui Su, and Qiang Ji CVPR 2019 We proposed a probabilistic model called Hierarchical Dynamic Model (HDM). Leveraging on Bayesian framework, the model parameters are allowed to vary across different sequences of data, which increase the capacity of the model to adapt to intra-class variations on both spatial and temporal extent of actions. Meanwhile, the generative learning process allows the model to preserve the distinctive dynamic pattern for each action class. |
 |
Wanru Xu, Jian Yu, Zhengjiang Miao, Lili Wan and Qiang ji IEEE Transaction on Circuits and Systmes for Video Technology, 2019 We propose a unified spatio-temporal deep Q-network (ST-DQN), consisting of a temporal Q-network and a spatial Q-network, to learn an optimized search strategy. Specifically, the spatial Q-network is a novel two-branch sequence-to-sequence deep Q-network, called TBSS-DQN. |
 |
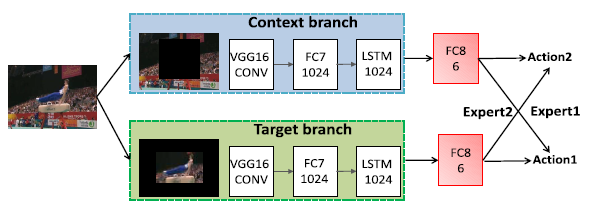
Wanru Xu, Zhengjiang Miao, Jian Yu, Qiang ji Neurocomputing 2019 We propose a principled dynamic model, called spatio-temporal context model (STCM), to simultaneously locate and recognize actions. The STCM integrates various kinds of contexts, including the temporal context that consists of the sequences before and after action as well as the spatial context in the surrounding of target. Meanwhile, a novel dynamic programming approach is introduced to accumulate evidences collected at a small set of candidates in order to detect the spatio-temporal location of action effectively and efficiently. |
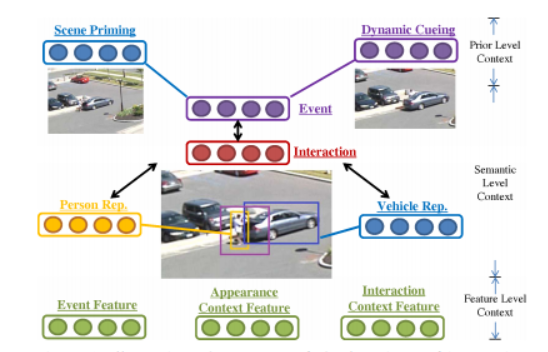 |
Xiaoyang Wang and Qiang ji We propose to exploit and model contexts from differnet levels to perform robust human event recognition. |
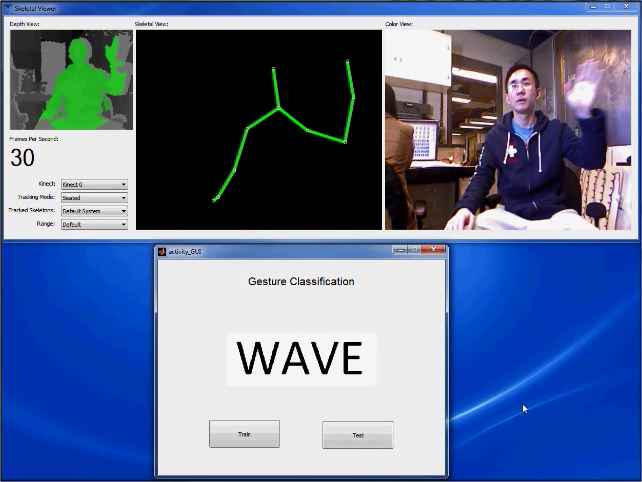 |
In this work, we proposed a Hidden Markov Model for human action recognition in real-time. We obtained the skeleton positions of human from Kinect depth camera and the builtin software. Based on the skeleton information, Hidden Markov Model is used to model the transition between the hidden states that define the action. |
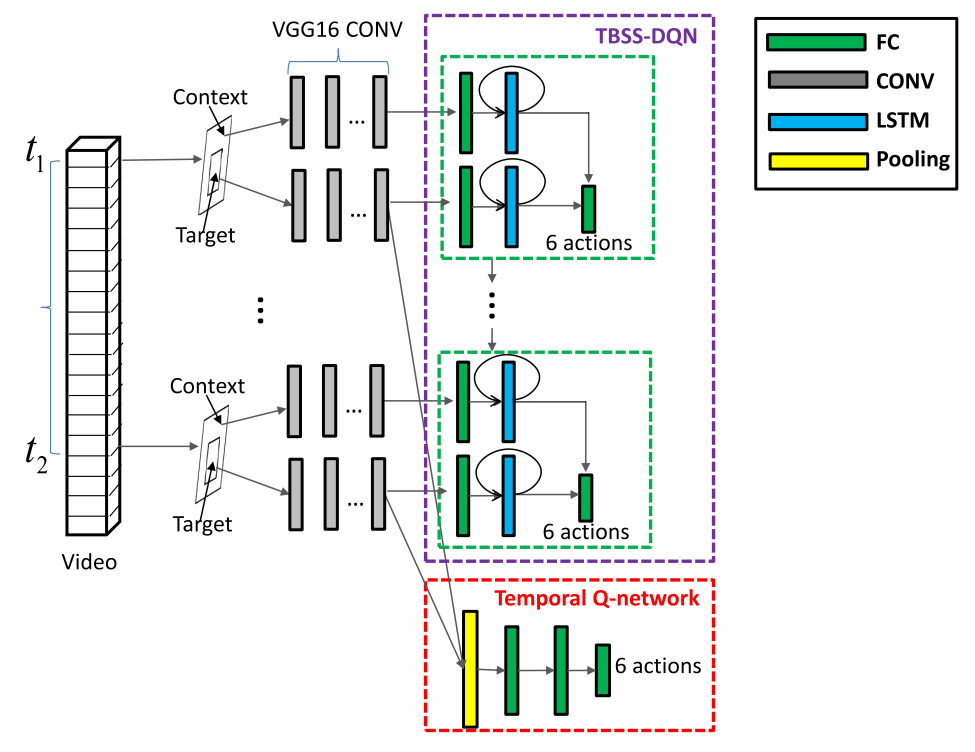 |
Wanru Xu, Jian Yu, Zhenjiang Miao, Lili Wan, Qiang Ji IEEE T-CSVT 2020 Human activity localization aims to recognize category labels and detect the spatio-temporal locations of activities in video sequences. Existing activity localization methods suffer from three major limitations. First, the search space is too large for three-dimensional (3D) activity localization, which requires the generation of a large number of proposals. Second, contextual relations are often ignored in these target-centered methods. Third, locating each frame independently fails to capture the temporal dynamics of human activity. To address the above issues, we propose a unified spatio-temporal deep Q-network (ST-DQN), consisting of a temporal Q-network and a spatial Q-network, to learn an optimized search strategy. Specifically, the spatial Q-network is a novel two-branch sequence-to-sequence deep Q-network, called TBSS-DQN. The network makes a sequence of decisions to search the bounding box for each frame simultaneously and accounts for temporal dependencies between neighboring frames. Additionally, the TBSS-DQN incorporates both the target branch and context branch to exploit contextual relations. The experimental results on the UCF-Sports, UCF-101, ActivityNet, JHMDB, and sub-JHMDB datasets demonstrate that our ST-DQN achieves promising localization performance with a very small number of proposals. The results also demonstrate that exploiting contextual information and temporal dependencies contributes to accurate detection of the spatio-temporal boundary. |
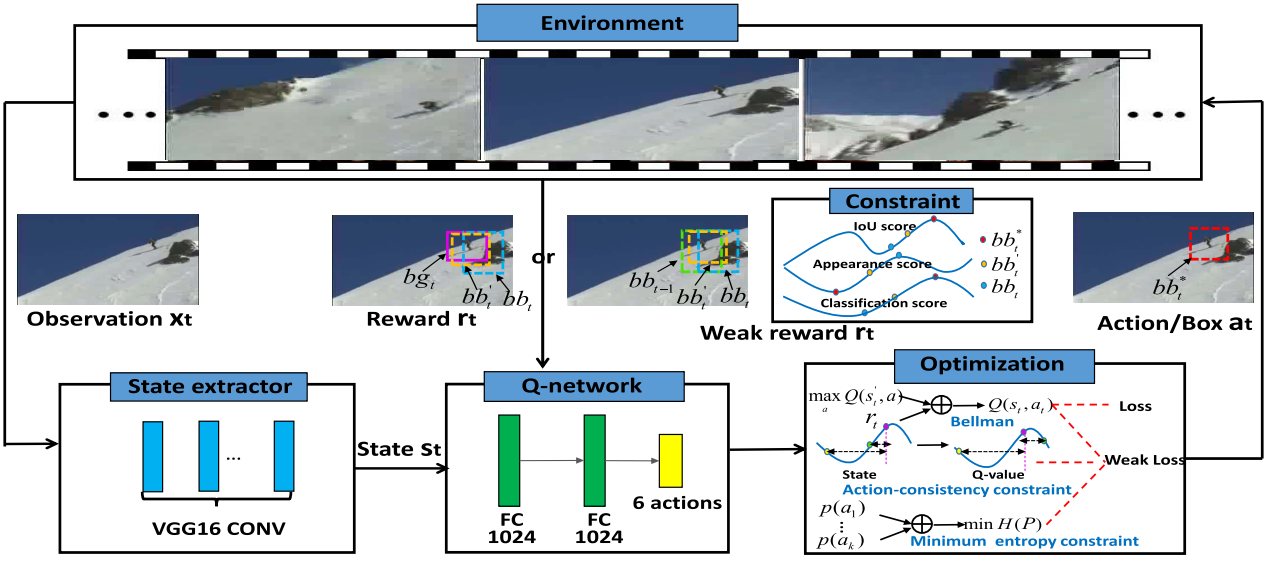 |
Wanru Xu, Zhenjiang Miao, Jian Yu, Qiang Ji IEEE TIP 2020 Human activity localization aims at recognizing contents and detecting locations of activities in video sequences. With an increasing number of untrimmed video data, traditional activity localization methods always suffer from two major limitations. First, detailed annotations are needed in most existing methods, i.e., bounding-box annotations in every frame, which are both expensive and time consuming. Second, the search space is too large for 3D activity localization, which requires generating a large number of proposals. In this paper, we propose a unified deep Q-network with weak reward and weak loss (DWRLQN) to address the two problems. Certain weak knowledge and weak constraints involving the temporal dynamics of human activity are incorporated into a deep reinforcement learning framework under sparse spatial supervision, where we assume that only a portion of frames are annotated in each video sequence. Experiments on UCF-Sports, UCF-101 and sub-JHMDB demonstrate that our proposed model achieves promising performance by only utilizing a very small number of proposals. More importantly, our DWRLQN trained with partial annotations and weak information even outperforms fully supervised methods. |
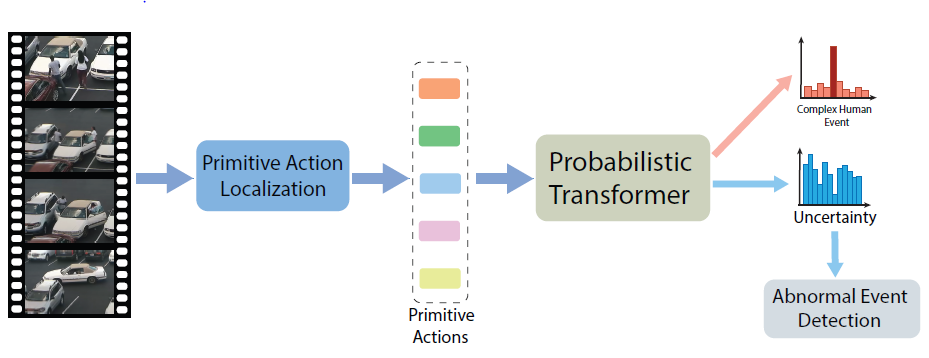 |
Hongji Guo, Alexander Aved, Collen Roller, Erika Ardiles-Cruz, Qiang Ji SPIE DCS 2023 Complex human event recognition requires recognizing not only the constituent primitive actions but also, more importantly, their long range spatiotemporal interactions. To meet this requirement, we propose to exploit the self-attention mechanism in the Transformer to model and capture the long-range interactions among primitive actions. We further extend the conventional Transformer to a probabilistic Transformer in order to quantify the event recognition confidence and to detect anomaly events. Specifically, given a sequence of human 3D skeletons, the proposed model first performs primitive action localization and recognition. The recognized primitive human actions and their features are then fed into the probabilistic Transformer for complex human event recognition. By using a probabilistic attention score, the probabilistic Transformer can not only recognize complex events but also quantify its prediction uncertainty. |
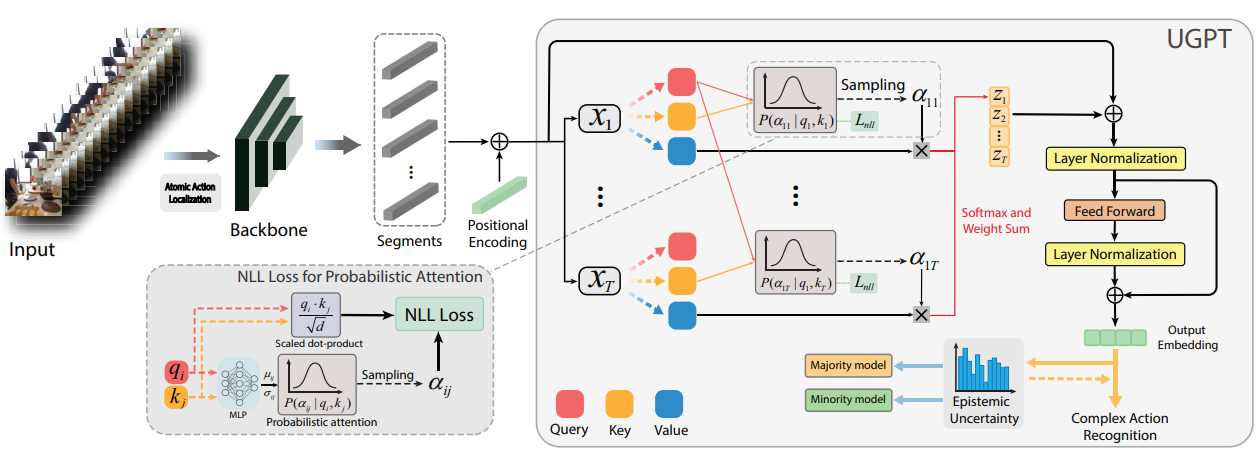 |
Hongji Guo, Hanjing Wang, Qiang Ji CVPR 2022 [Project Page] In this work, we introduce uncertainty-guided probabilistic Transformer (UGPT) for complex action recognition. The selfattention mechanism of a Transformer is used to capture the complex and long-term dynamics of the complex actions. By explicitly modeling the distribution of the attention scores, we extend the deterministic Transformer to a probabilisticTransformer in order to quantify the uncertainty of the prediction. The model prediction uncertainty is used to improve both training and inference. Specifically, we propose a novel training strategy by introducing a majority model and a minority model based on the epistemic uncertainty. During the inference, the prediction is jointly made by both models through a dynamic fusion strategy. |
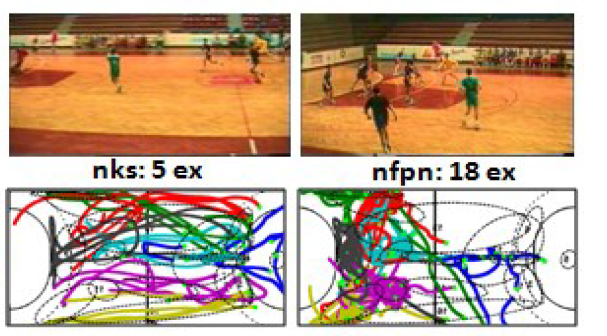 |
Eran Swears, Anthony Hoogs, Qiang Ji and Kim Boyer CVPR 2014 We propose a novel structure learning solution that fuses the Granger Causality statistic, a direct measure of temporal dependence, with the Adaboost feature selection algorithm to automatically constrain the temporal links of a DBN in a discriminative manner. This approach enables us to completely define the DBN structure prior to parameter learning, which reduces computational complexity in addition to providing a more descriptive structure. |
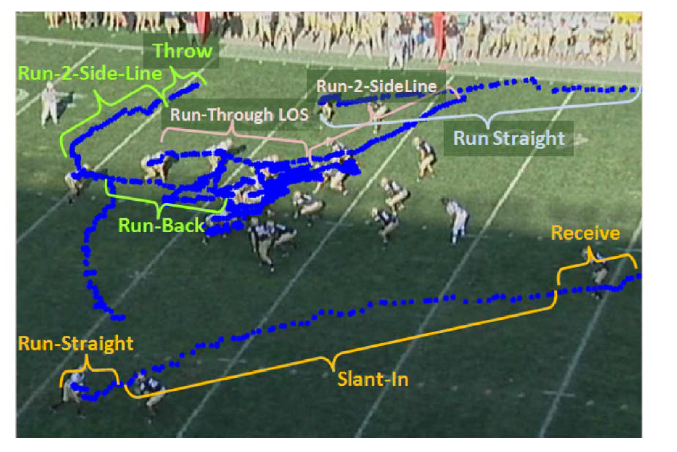 |
Yongmian Zhang, Yifan Zhang, Eran Swears, Natalia Larios, Ziheng Wang and Qiang Ji TPAMI 2014 We introduce the interval temporal Bayesian network (ITBN), a novel graphical model that combines the Bayesian Network with the interval algebra to explicitly model the temporal dependencies among basic human actions over time intervals. Advanced machine learning methods are introduced to learn the ITBN model structure and parameters. |
Upper body gesture recognition
Gesture recognition for teaching mathematicsAction recognition:



Clapping Throw Waving