
The Intelligent Systems Laboratory at RPI has long performed research related to human gesture, action, and activity recognition. Specifically, we have performed research in human body detection and tracking, 2D/3D body pose estimation, body landmark/part detection and tracking, body gesture recognition, human event and complex activity recognition. These efforts have been supported by different governmental agencies including DARPA, ARO, ONR, AFOSR, DOT, and NSF.
Action localization aims at recognizing and detecting the spatial-temporal locations of human actions in video sequences. It has various applications such as industrial manufacturing, sports analysis, etc. We developed multiple methods to handle this task including graphical models based and deep-learning based methods. Our recent works include two streams deep Q-networks which capture spatial and temporal information using our proposed ST-DQN module.
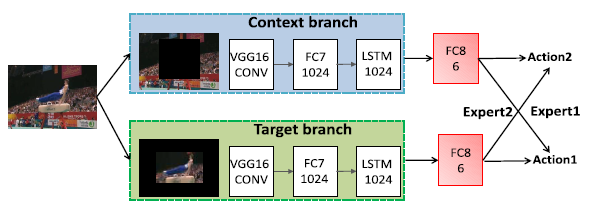 |
Wanru Xu, Jian Yu, Zhengjiang Miao, Lili Wan and Qiang ji IEEE Transaction on Circuits and Systmes for Video Technology, 2019 We propose a unified spatio-temporal deep Q-network (ST-DQN), consisting of a temporal Q-network and a spatial Q-network, to learn an optimized search strategy. Specifically, the spatial Q-network is a novel two-branch sequence-to-sequence deep Q-network, called TBSS-DQN. |
 |
Wanru Xu, Zhengjiang Miao, Jian Yu, Qiang ji Neurocomputing 2019 We propose a principled dynamic model, called spatio-temporal context model (STCM), to simultaneously locate and recognize actions. The STCM integrates various kinds of contexts, including the temporal context that consists of the sequences before and after action as well as the spatial context in the surrounding of target. Meanwhile, a novel dynamic programming approach is introduced to accumulate evidences collected at a small set of candidates in order to detect the spatio-temporal location of action effectively and efficiently. |
Gesture and action recognition is an important topic in computer vision which has many applications such as visual surveillance, human-robot interaction, etc. According to different data sources, we developed recognition methods using skeleton data and image data.
Skeleton-based action recognition is becoming popular due to the easier ways to get the skeleton data like Microsoft Kinect and high-efficiency estimation algorithms. Skeleton data contain only 2D or 3D positions of human key points, providing highly abstract information that is free of environmental noises (e.g. background clutter, lighting conditions, clothing), allowing action recognition algorithms to focus on the robust features of the action. We use Hidden Markon Model (HMM) to model the human actions. Our recent works contins using graph convolution and LSTM to model human actions and recognize them in complicated environments. It can also be implemented for real-time applications with high robustness.
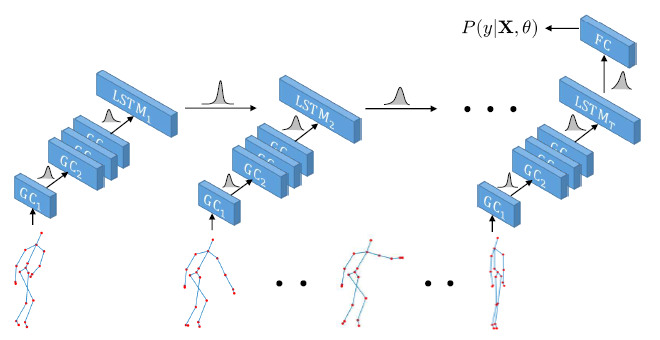 |
Rui Zhao, Kang Wang, Hui Su, Qiang Ji ICCV 2019 We utilize graph convolution to extract structure-aware feature representation from pose data by exploiting the skeleton anatomy. Long short-term memory (LSTM) network is then used to capture the temporal dynamics of the data. Finally, the whole model is extended under the Bayesian framework to a probabilistic model in order to better capture the stochasticity and variation in the data. |
Selected demos:



Clapping Throw Waving
Action recognition from videos: 2D images (videos) are more common and is the main resource we get the data. We developed methods using dynamic models to recognize human action from video sequences. Dynamic graphical models can explicitly model the spatial and temporal varations in human motion sequences. It is intuitive to human and easy for us to deal with the uncertainty and complexity in different situations. Our recent works includes multi-layer HSMM with adversarial Bayesian inference for human motion systhesis, Hierarchical Dynamic Model(HDM) for human action recognition. We also developed real-time demos based on HMM and its variants.
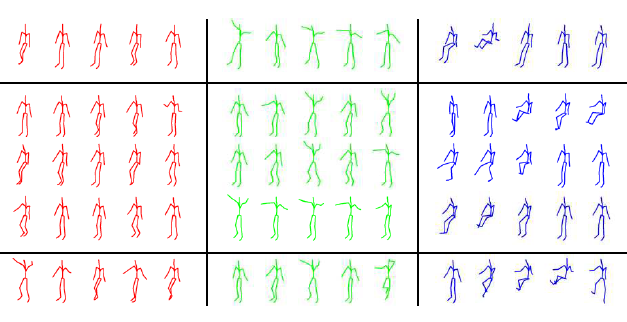 |
Rui Zhao, Hui Su, and Qiang Ji CVPR 2020 We proposed a generative probabilistic model for human motion synthesis. It has a hierarchy of three layers. At the bottom layer, we utilize Hidden semi-Markov Model(HSMM), which explicitly models the spatial pose, temporal transition and speed variations in motion sequences. At the middle layer, HSMM parameters are treated as random variables which are allowed to vary across data instances in order to capture large intra- and inter-class variations. At the top layer, hyperparameters define the prior distributions of parameters, preventing the model from overfitting. |
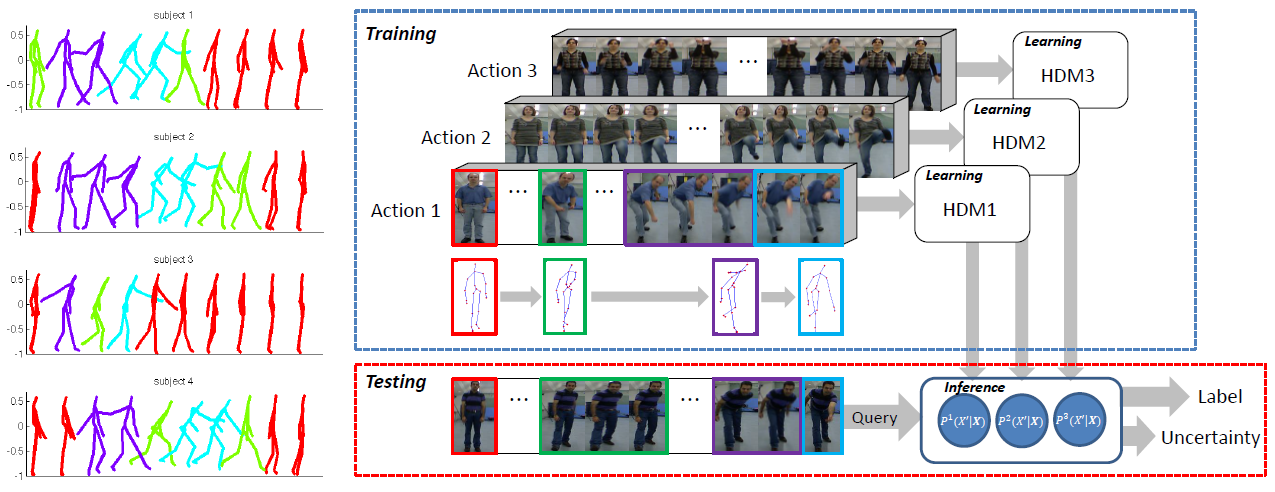 |
Rui Zhao, Hui Su, and Qiang Ji CVPR 2019 We proposed a probabilistic model called Hierarchical Dynamic Model (HDM). Leveraging on Bayesian framework, the model parameters are allowed to vary across different sequences of data, which increase the capacity of the model to adapt to intra-class variations on both spatial and temporal extent of actions. Meanwhile, the generative learning process allows the model to preserve the distinctive dynamic pattern for each action class. |
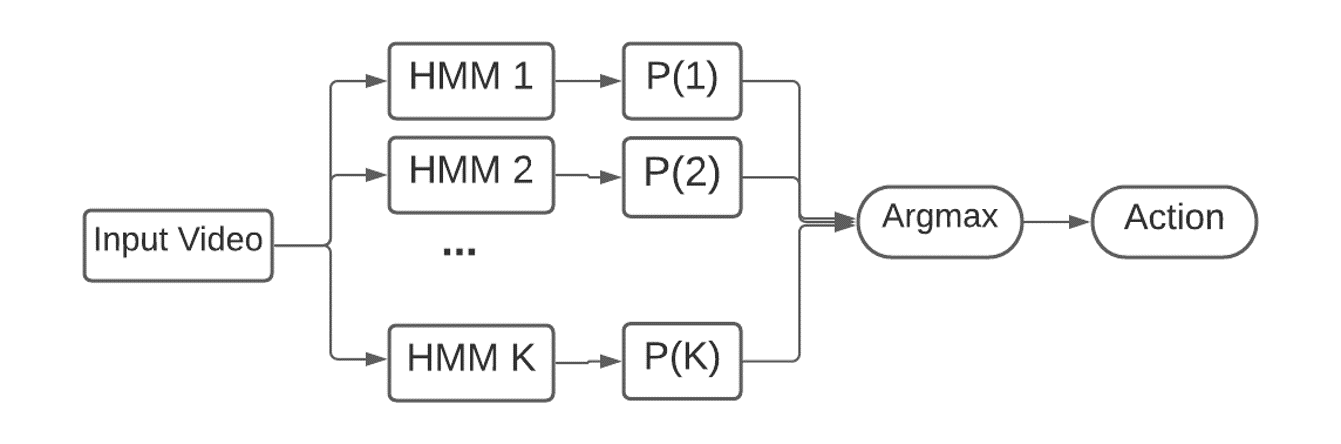 |
Basic dynamic model like Hidden Markov Model (HMM) is widely used in action recognition tasks, we train one HMM for each action class and choose the class with highest joint probablity during the recognition process as the result. The whole recognition process can be considered as a maximum model likelihood task. Related publications: (1) An Adversarial Hierarchical Hidden Markov Model for Human Pose Modeling and Generation (AAAI 2018) (2) An Immersive System with Multi-modal Human-computer Interaction (FG 2018) Demo |
Complex human activity consists of a structural combination of the atomic actions that happen in parallel or in sequence over a period of time. Complex activities such as cooking, sports activities are made of many "sub-actions" like washing, jumping. As complex activities are more common than sub-actions in daily lives and encode the higher understanding of human activities, it is important to model them and recognize them accurately and efficiently. Previous works includes using advanced dynamic Bayesian networks to model complex human activities.
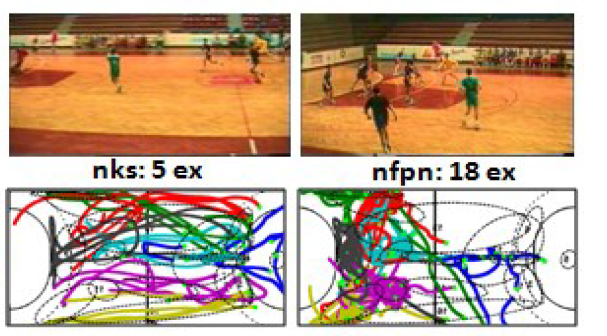 |
Eran Swears, Anthony Hoogs, Qiang Ji and Kim Boyer CVPR 2014 We propose a novel structure learning solution that fuses the Granger Causality statistic, a direct measure of temporal dependence, with the Adaboost feature selection algorithm to automatically constrain the temporal links of a DBN in a discriminative manner. This approach enables us to completely define the DBN structure prior to parameter learning, which reduces computational complexity in addition to providing a more descriptive structure. |
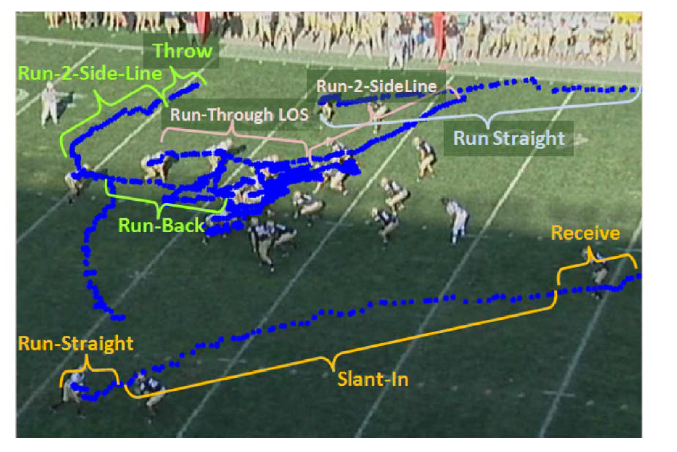 |
Yongmian Zhang, Yifan Zhang, Eran Swears, Natalia Larios, Ziheng Wang and Qiang Ji TPAMI 2014 We introduce the interval temporal Bayesian network (ITBN), a novel graphical model that combines the Bayesian Network with the interval algebra to explicitly model the temporal dependencies among basic human actions over time intervals. Advanced machine learning methods are introduced to learn the ITBN model structure and parameters. |
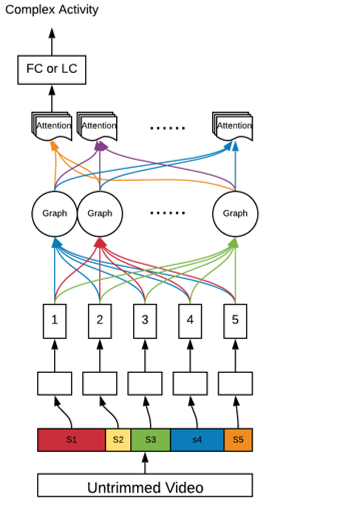 |
In NLP tasks, transformer network is widely used for solving long-range dependency problem and reducing the computation quantity. Taking advantages of the self-attention mechanism, it can well capture and long-range dependency for the whole input by pair-wise querying and enable highly-efficient parallel computing. Inspired by the Transformer, we propose to use attention-based model to capture the temporal relationships between sub-actions so that the local information can contribute to our understanding of the complex action. In our task, we model a complex human activity as a "visual sentence" consisting of visual words (basic actions) that happen following certain temporal order. We first use frame-wise temporal action segmentation methods like Temporal Convolution Networks(TCN) or SSTDA to localize and recognize sub-actions, then feed the extracted sub-action labels or features into the transformer networks to output the complete embedding. Finally, the embeddings go through a linear classifier or fully-connected layer to output the complex activity. Experimental results on benchmark datasets show that our method outperforms SOTA complex human activity recognition methods. Ongoing |