
3D Face modeling is an active research area in computer vision, with an increasing attention in various applications such as 3D animation, AR/VR, human-computer interaction, etc. Generally a 3D face shape can be modelled by the 3D morphable model (3DMM), which is a statistic model consisting of parameterized 3D shapes. Typically, a geometric 3DMM divides the space of a 3D facial shape into an identity dimension and an expression dimension, which are spanned by identity bases and expression bases respectively. The geometric bases are usually constructed from large scale 3D human facial scans.
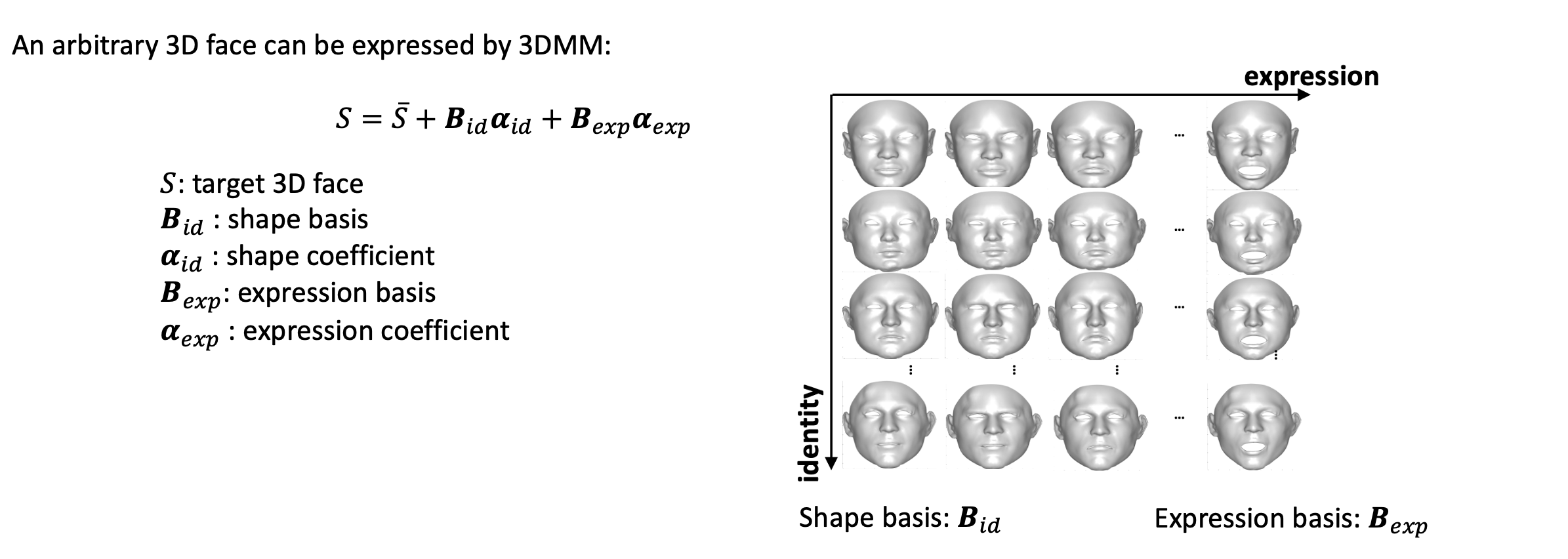
Figure 1. 3D face shape bases and expression bases.
The problem of monocular image-based 3D face reconstruction can be solved by constructing the correspondency between image pixels and 3D face vertices through a weak perspective camera projection. Recovering the 3D face from image includes the shape & expression coefficients, pose and camera parameters. Sparse correspondence such as facial landmarks can be utilized to performe a coarse 3DMM fitting as initialization and dense correspondence can be constructed based on texture rendering.

Figure 2. construct sparse correspondence between image and 3D face through locating facial landmarks.
There have been tremendous improvements for 3D facial geometry recovery. However, it is still challenging to reconstruct accurate facial motions or expressions in 3D space. 3D facial blendshapes have been widely used as an convenient 3D engine for facial expression modeling and animation. The blendshape-based 3DMM can also be divided into shape bases and expression bases but different with PCA-based 3DMMs, each expression blendshape entails only local deformations relative to the neural blendshape, hence making it plausible to sementically model subtle facial motions caused by facial action units (AUs). Various approaches have been introduced for generating facial blendshapes given 3D data of subjects, like 3D scans and 3D point clouds. However, few of them considers generating AU-based blendshapes for accurate facial motion recovery. In our work [1], we propose a deep learning framework that explicitly learns personalized and AU-explainable 3D blendshapes for accurate 3D face reconstruction with acquiring any 3D ground-truth data.
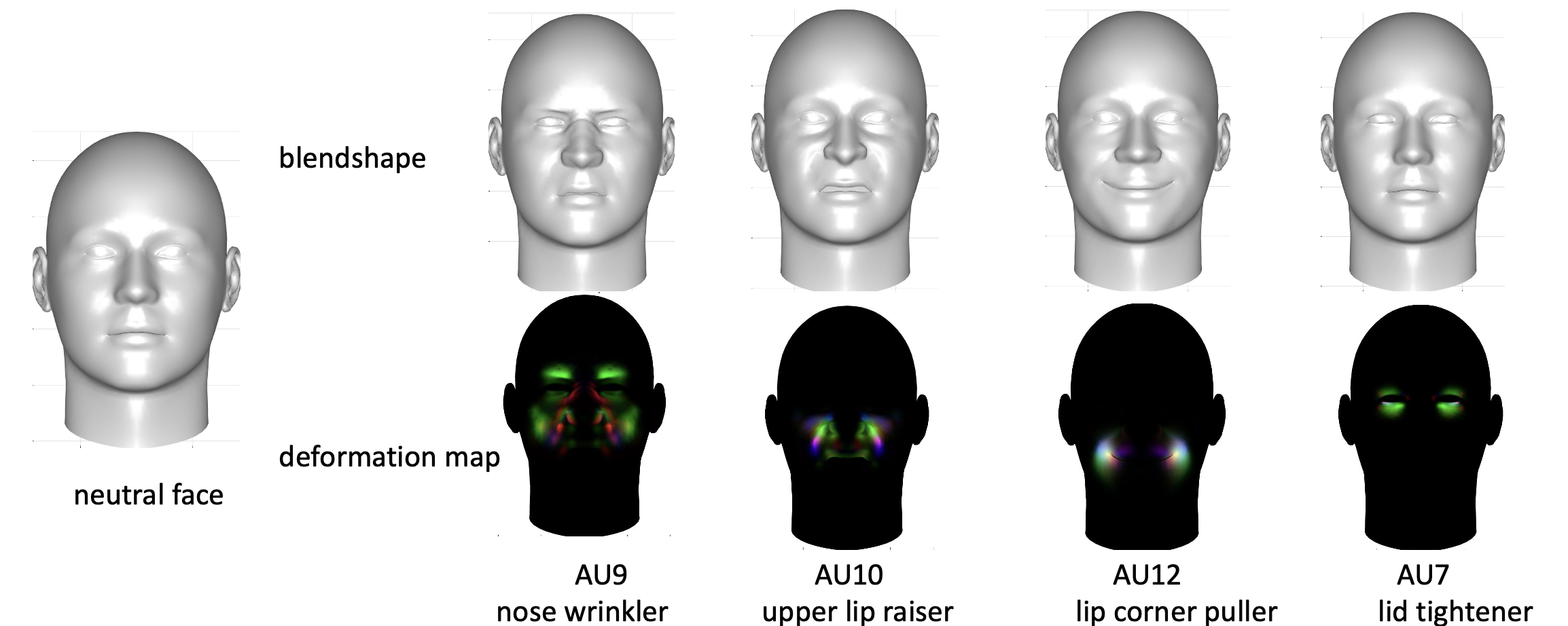
Figure 3. 3D AU-based blendshapes and deformation maps.
Facial action unit recognition is an important technique for facial expression analysis. In this work [1], we train a deep model to learn AU-interpretable 3D blendshapes given any input image by utilizing AU regularizations as contraints. In particular, we first build a basic module for regressing all 3D reconstruction parameters, including pose and camera parameters, identity coefficients β, AU-blendshape coefficients η, expression coefficients α, texture coefficients δ and illumination parameters γ. Then through a weighted combination module we are able to construct AU-specific blendshapes corresponding to the subject identity. During training, we explicitly incorporate AU relationships and AU labels as AU-regularization loss. Experimental results demonstrate that we can achieve the state-of-art 3D reconstruction accuracy with the personalized AU-blendshapes and visualizarion results shows more realistic reconstructions, especially for subtle motions in the eye and mouth regions.

Figure 4. bridging the learning process of 3D blendshapes with AU labels and relationships.

Figure 5. state-of-the-art 3D reconstruction results.
Figure 6. predicted AU-blendshapes for different testing subject.

Figure 7. subtle motion reconstruction on testing dataset.

Figure 8. Expression manipulation by modifying corresponding 3D AU coefficients.
[1] Kuang, Chenyi, Zijun Cui, Jeffrey O. Kephart, and Qiang Ji. "AU-Aware 3D Face Reconstruction through Personalized AU-Specific Blendshape Learning." In European Conference on Computer Vision, pp. 1-18. Springer, Cham, 2022. PDF